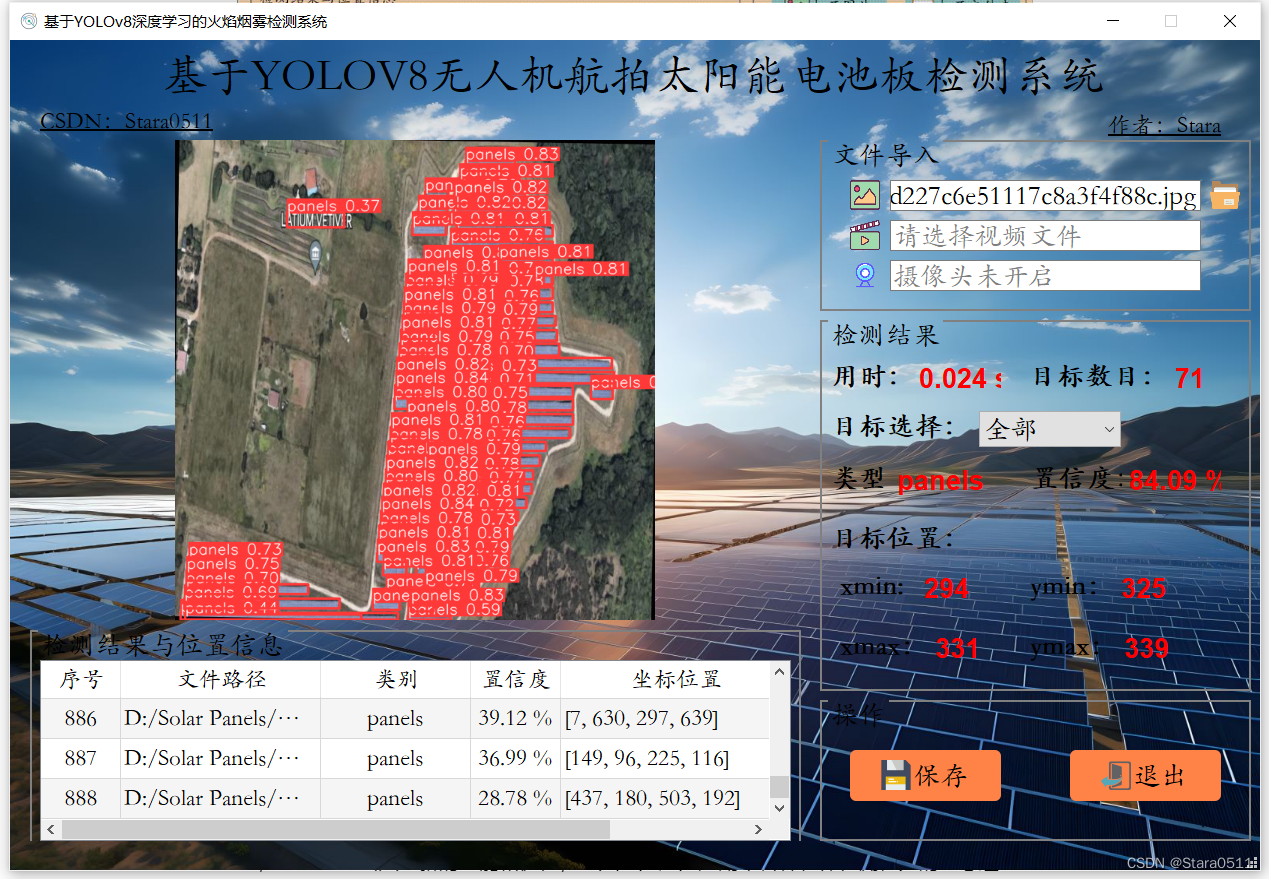
浙大&蚂蚁OneKE大模型知识抽取框架是由蚂蚁集团和浙江大学联合研发的,它是一个具备中英文双语、多领域多任务泛化知识抽取能力的大模型知识抽取框架。OneKE不仅提供了完善的工具链支持,还以开源形式贡献给了OpenKG开放知识图谱社区[1][2][3]。此外,OneKE旨在帮助处理信息抽取、文本数据结构化和知识图谱构建等任务[11][12]。
浙大&蚂蚁OneKE大模型知识抽取框架的具体技术原理是什么?
浙大&蚂蚁OneKE大模型知识抽取框架的具体技术原理并未在我搜索到的资料中直接描述。然而,从相关信息可以推断一些基本概念和特点。OneKE是由蚂蚁集团和浙江大学联合研发的,它具备中英文双语、多领域多任务的泛化知识抽取能力,并提供了完善的工具链支持[14]。这表明OneKE可能采用了先进的自然语言处理(NLP)技术和机器学习算法来实现其功能,尽管具体的算法原理和技术细节没有被明确提及。
自动知识抽取的核心概念包括从文本数据到结构化知识的转换,涉及到的核心技术和方法可能包括但不限于文本预处理、实体识别、关系抽取、知识图谱构建等步骤[15]。虽然这些是自动知识抽取领域的一般性描述,但它们为理解OneKE的工作原理提供了一定的背景信息。
此外,其他开源知识图谱抽取框架如DeepKE的存在[16],表明了当前技术社区对于提高知识抽取效率和准确性的持续探索和创新。尽管DeepKE专注于中文知识图谱抽取,但它所采用的技术和方法可能与OneKE有相似之处,特别是在处理大规模文本数据和构建知识图谱方面。
虽然没有直接的证据描述OneKE的具体技术原理,但可以合理推测它结合了最新的自然语言处理技术和机器学习算法,以实现高效的中英文双语、多领域知识抽取,并通过开源形式促进知识图谱社区的发展[14]。
OneKE大模型在信息抽取、文本数据结构化和知识图谱构建方面的应用案例有哪些?
OneKE大模型在信息抽取、文本数据结构化和知识图谱构建方面的应用案例主要体现在以下几个方面:
- 信息抽取:OneKE框架旨在帮助处理信息抽取任务,这意味着它能够从大量非结构化的文本数据中提取出有价值的信息。
- 文本数据结构化:通过将非结构化的文本数据转换为结构化的形式,OneKE框架有助于提高数据的可用性和可操作性。
- 知识图谱构建:OneKE框架的一个核心功能是构建高质量的知识图谱。这涉及到从海量数据中萃取结构化知识,并建立知识要素间的逻辑关联。这样的知识图谱不仅可以用于实现可解释的推理决策,还可以增强大模型的稳定性和缓解幻觉问题[18]。
- 解决知识图谱大规模落地的关键难题:OneKE框架特别关注于基于非结构化文档的知识构建问题,这是知识图谱大规模落地的关键难题之一。通过有效处理这一问题,OneKE有助于推动知识图谱在更广泛领域的应用[20]。
OneKE大模型在信息抽取、文本数据结构化和知识图谱构建方面的应用案例涵盖了从基础的信息抽取到复杂的知识图谱构建等多个层面,展现了其在处理大规模非结构化数据和构建高质量知识图谱方面的重要价值和潜力。
如何使用OneKE大模型进行中英文双语知识抽取?
使用OneKE大模型进行中英文双语知识抽取的方法可以概括为以下几个步骤:
- 了解OneKE模型:首先,需要对OneKE模型有一个基本的了解。OneKE是由蚂蚁集团和浙江大学联合研发的大模型知识抽取框架,它具备中英文双语、多领域多任务的泛化知识抽取能力,并提供了完善的工具链支持[22]。这意味着OneKE能够处理中英文数据,适用于多种领域的知识抽取任务。
- 获取OneKE模型:由于OneKE以开源形式贡献[22],用户可以通过官方渠道或相关平台获取到OneKE模型的代码或预训练模型。这一步骤是实现知识抽取的前提条件。
- 准备数据:在使用OneKE进行知识抽取之前,需要准备好用于训练或测试的数据集。这些数据集应该包含中英文文本,且覆盖不同的领域和主题,以便模型能够学习到丰富的知识并泛化到新的领域和任务中[23]。
- 配置和训练模型:根据提供的工具链支持,用户可能需要对OneKE模型进行一些配置,比如选择合适的参数、调整模型结构等,以适应特定的知识抽取任务。然后,使用准备好的数据集对模型进行训练。这个过程中,可以参考相关的训练方法和实验分析来优化模型性能[24]。
- 知识抽取与应用:训练完成后,就可以使用OneKE模型进行中英文双语知识抽取了。抽取的知识可以用于多种应用场景,如构建知识图谱、智能问答系统等[23]。此外,OneKE还支持基于Schema的信息抽取,这意味着用户可以根据特定的结构化模板来指导知识抽取过程,进一步提高抽取的准确性和效率[23]。
总之,使用OneKE大模型进行中英文双语知识抽取涉及到对模型的基本了解、获取模型、准备和处理数据、模型配置与训练以及最终的知识抽取与应用等多个步骤。通过遵循上述步骤,用户可以有效地利用OneKE模型进行中英文双语知识抽取。
OpenKG开放知识图谱社区如何利用OneKE大模型进行贡献和开发?
OpenKG开放知识图谱社区可以通过多种方式利用OneKE大模型进行贡献和开发。首先,OpenKG致力于促进以中文为核心的知识图谱数据的开放、互联与众包,以及知识图谱工具、模型和平台的开源开放[27]。这意味着社区成员可以参与到知识图谱的数据收集、整理和共享中,为OpenKG贡献自己的力量。
通过参与OpenKG项目,社区成员可以利用OneKE大模型进行知识图谱问答工具的开发。例如,ChatKBQA就是基于微调开源大模型的知识图谱问答工具[31]。这表明社区成员可以通过微调OneKE大模型,开发出能够回答问题的智能工具,进一步丰富和完善OpenKG的知识图谱。
此外,OpenKG还提供了cnSchema这样的开放的中文知识图谱Schema参考标准[32]。社区成员可以利用OneKE大模型对这些Schema进行分析和应用,帮助构建更加准确和丰富的中文领域知识图谱。
OpenKG开放知识图谱社区可以通过参与数据收集与共享、开发基于OneKE大模型的知识图谱问答工具,以及利用cnSchema等Schema参考标准进行知识图谱的构建和优化,来利用OneKE大模型进行贡献和开发。这些活动不仅有助于推动知识图谱的发展,也为社区成员提供了实践和学习的机会。
OneKE大模型与其他知识抽取框架相比有哪些独特优势?
OneKE大模型与其他知识抽取框架相比,具有以下独特优势:
- 开源与社区支持:OneKE是由蚂蚁集团和浙江大学联合研发,并且已经宣布开源并捐赠给OpenKG开放知识图谱社区[36]。这意味着OneKE不仅能够获得来自蚂蚁集团和浙江大学的技术支持,还能够借助开源社区的力量进行持续的改进和优化,从而在功能、性能等方面保持领先。
- 强大的自学习能力:根据阿里云开发者社区的报道,大模型的一个重要优势是其强大的自学习能力。通过将大数据“喂”给模型,大模型能够增强自身的智能程度[35]。这表明OneKE可能具备通过大量数据自我学习和适应的能力,从而在处理复杂数据模式和关联关系时表现出色。
- 泛化能力和语义表达:大模型的优势还包括更好的表示能力、泛化能力和语义表达[33]。这些特点使得大模型能够更好地理解和处理复杂的数据模式和关联关系。因此,OneKE可能在理解文本、图像等非结构化数据方面具有更强的能力,这对于知识抽取尤为重要。
- 本地数据处理效率和隐私保护:端侧大模型具有的本地数据处理效率更高,节省云端服务器带宽和算力成本,同时对用户数据有更好的隐私保护[34]。虽然这一点直接关联的是端侧大模型,但考虑到OneKE作为大模型的一种,它也可能受益于类似的优化,提供更高效的数据处理能力和更好的隐私保护。
OneKE大模型的独特优势在于其开源性质、强大的自学习能力、优秀的泛化能力和语义表达能力,以及可能的高效数据处理和隐私保护能力。这些优势使其在知识抽取领域中具有较强的竞争力。
参考资料
1. OneKE
2. 开放开源!蚂蚁集团浙江大学联合发布开源大模型知识抽取框架OneKE [2024-04-22]
3. 蚂蚁集团浙江大学联合发布开源大模型知识抽取框架OneKE - 知乎 [2024-04-22]
4. OneKE: 中英双语知识抽取大模型- 工具- 开放知识图谱 [2024-04-18]
5. 开放开源!蚂蚁集团浙江大学联合发布开源大模型知识抽取框架OneKE_图谱_领域_文本 [2024-04-18]
6. 蚂蚁集团、浙江大学联合发布开源大模型知识抽取框架OneKE-CSDN博客 [2024-04-19]
7. 蚂蚁集团、浙江大学联合发布开源大模型知识抽取框架OneKE [2024-04-19]
8. 蚂蚁集团等发布开源大模型知识抽取框架OneKE - 腾讯新闻 [2024-04-20]
9. 蚂蚁集团、浙江大学联合发布开源大模型知识抽取框架OneKE-人工智能 [2024-04-19]
10. 蚂蚁集团开源代码大模型CodeFuse!(含魔搭体验和最佳实践)-阿里云开发者社区 [2023-09-12]
11. 蚂蚁集团等发布开源大模型知识抽取框架OneKE - 中文科技资讯 [2024-04-19]
12. 蚂蚁集团等发布开源大模型知识抽取框架OneKE - Chinaz.com [2024-04-19]
13. 中英双语大模型知识抽取框架 - 魔搭社区
14. 开放开源!蚂蚁集团浙江大学联合发布开源大模型知识抽取框架OneKE-CSDN博客 [2024-04-18]
15. 自动知识抽取:从文本数据到结构化知识的转换- 掘金 [2024-01-08]
16. 开源中文知识图谱抽取框架 DeepKE:深度解析与实战应用 [2024-02-16]
18. 开放开源!蚂蚁集团浙江大学联合发布开源大模型知识抽取框架OneKE [2024-04-19]
19. 蚂蚁集团等发布开源大模型知识抽取框架OneKE - AIGC - 蓝天采集器 [2024-04-21]
20. OneKE
21. 2024开篇之大模型遇见信息抽取:常见数据增强、形式化语言及可练手小模型开源项目 - 智源社区 [2024-01-03]
22. 无主题
23. OpenSPG v0.0.3 发布,新增大模型统一知识抽取&图谱可视化原创 [2024-04-25]
24. 开箱即用的文本理解大模型 - TechBeat
25. 开源大模型食用指南 - AIbase
26. 动手学大模型应用开发
27. OpenKG
28. OpenKG - OpenKG Consortium
29. 大模型API 推理全指南| OneAPI + Ollama + vLLM + ChatTool - 知乎专栏 [2024-04-23]
30. 通义千问API:让大模型使用各种工具 - 阿里云开发者社区 [2024-02-26]
31. OpenKG.CN - 开放的中文知识图谱
32. cnSchema - 开放的中文知识图谱 - OpenKG
33. 大模型真正的优势在于其容量,而不是能小样本学习? - 知乎
34. 加速分化:关于大模型走势的十个判断 - 36氪 [2024-03-15]
35. 大模型为什么是深度学习的未来? - 阿里云开发者社区 [2023-02-16]
36. 开源日报| 有关LLAMA-3、大模型开源与闭源;智能体四大设计模式; [2024-04-19]